吴恩达 2026《AI 提示词工程》Module 2 全笔记:把 AI 真正变成你的思考伙伴

Module 1 解决「找信息」的问题,Module 2 把 AI 真正用起来——当思考伙伴、当编辑、当评审。
这 8 节课最颠覆我认知的一个共识:AI 默认是个会拍马屁的高智商应届生。所有 prompt 工程的底层逻辑,都是绕开它的「想取悦你」本能,逼它给你真正有用的东西。
按「截图 + 1 句解读 + 1 个模板」三段式整理:
Day 1·头脑风暴:让 AI 走出「常识答案」舒适区
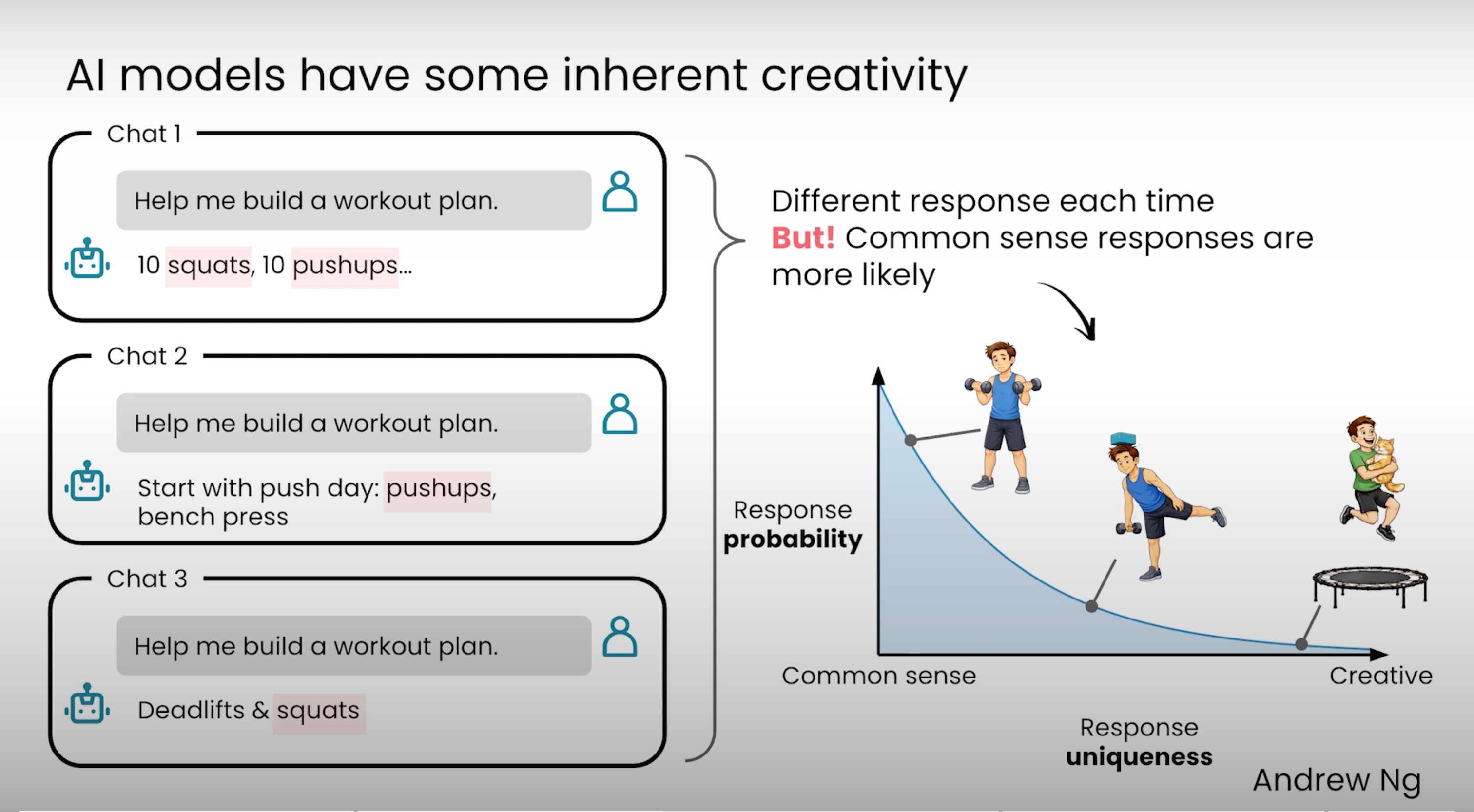
💡 1 句话解读: AI 默认给"常识答案"(深蹲、俯卧撑),因为互联网上同类文本最多——想要创意答案(蹦床破节、猫触发微训练),必须给足上下文 + 多轮迭代反馈。
📋 模板·迭代式头脑风暴
帮我头脑风暴:[问题]
我的背景上下文:
- 现状:[关键约束]
- 资源:[手头有什么]
- 已经试过的:[列举 2-3 个不想再试的方向]
- 期望角度:[创意/务实/冷门/逆向]
请给我 5 个不同方向的方案。每个方案 30 字以内,先列清单,
等我给反馈后再展开细节。
—— 我看完会说「方案 X 喜欢哪部分、Y 不喜欢哪部分」,
你基于反馈再生成 5 个新方案,迭代 3 轮。
Day 2·上下文管理:你拥有的容量是 4-5 本《哈利·波特》
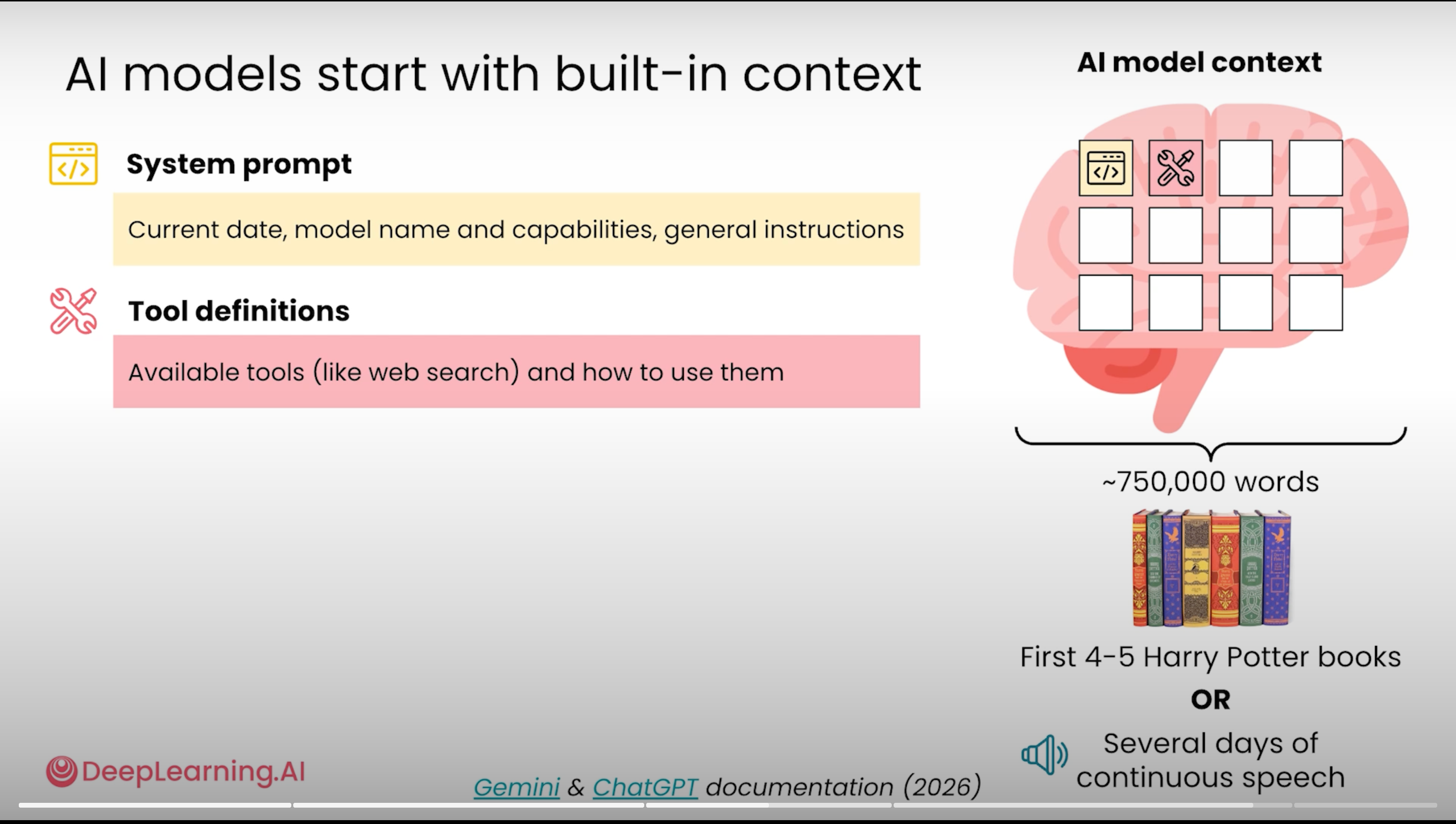
💡 1 句话解读: 主流 AI 的 context 能装下约 75 万词(4-5 本《哈利·波特》),大多数人严重低估这个容量——但话题切换时一定要新开 chat,旧上下文会污染新答案。
📋 模板·上下文打包(一次发完)
我准备问你一个复杂问题,先把所有背景一次性给你:
【我是谁】[职业 / 身份 / 决策角色]
【我在做什么】[当前项目 / 任务]
【关键数据】[现状指标 / 时间约束 / 预算]
【我的目标】[期望的产出形式]
【已经试过】[避免重复建议]
【期望输出】[报告 / 清单 / 决策建议 / 选项对比]
正式问题:[你的问题]
请基于以上全部信息回答,必要时引用具体细节。
Day 3·AI 桌面 Agent:让它读你电脑上的文件
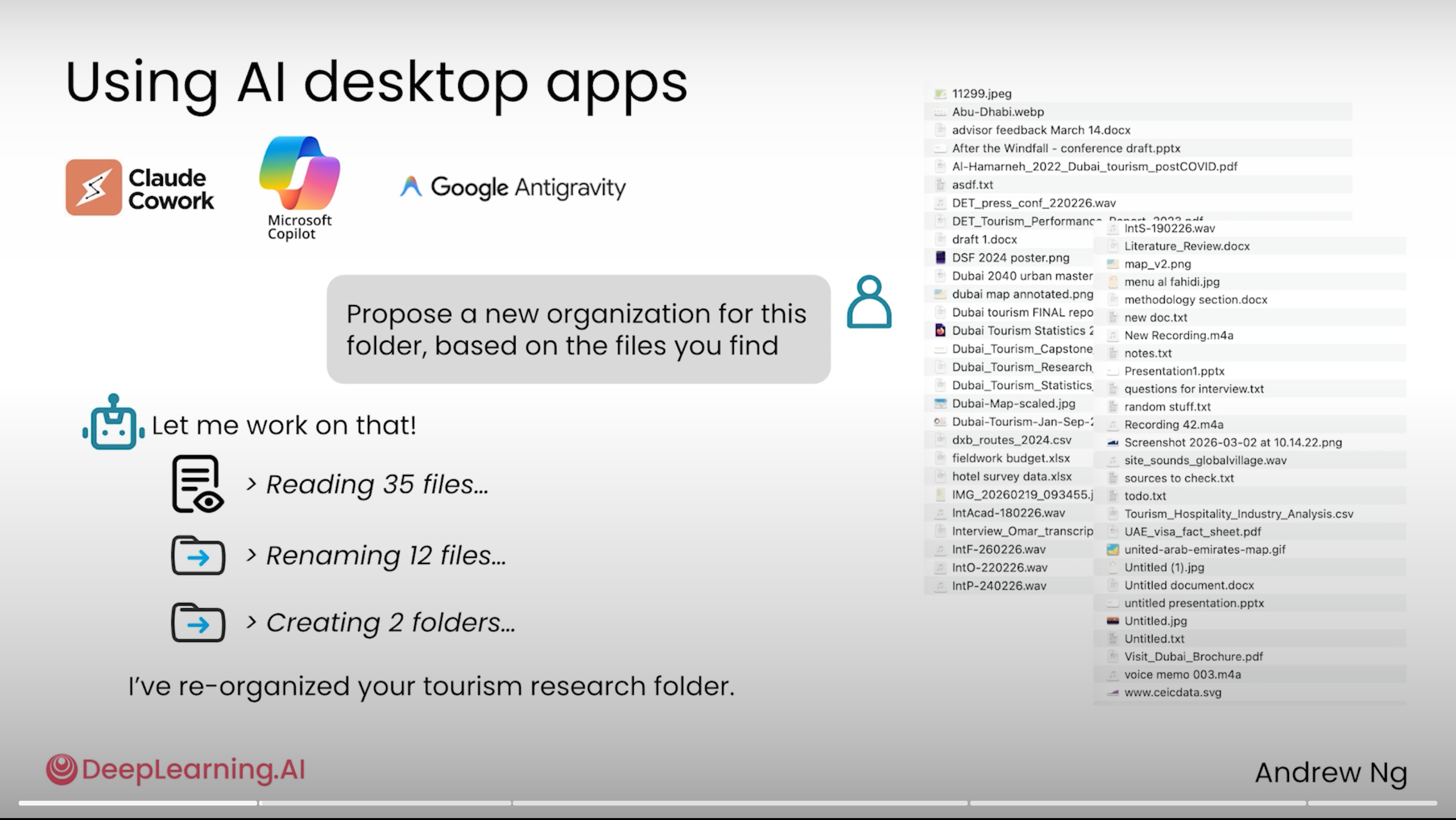
💡 1 句话解读: Claude Cowork / Microsoft Copilot / Google Antigravity 能读写你电脑文件——但永远先让它出方案、不要直接执行,删的文件不进回收站,覆盖的文件没历史。
📋 模板·安全三步走(强制 propose → review → execute)
任务:[你想做的事,比如「整理这个文件夹」]
请按以下顺序执行:
Step 1:先列出你打算读的文件(不要读内容)
+ 你打算执行的所有动作(move/rename/delete/create)
+ 风险评估(哪些是不可逆的)
STOP,等我审查后再继续。
Step 2:我说"OK"后,按顺序执行
每完成一个动作输出一行日志
遇到任何意外立刻停下问我。
⚠️ 严禁:删除任何文件(移到 .trash/ 文件夹代替)
⚠️ 严禁:触碰 .git / node_modules / .env*
Day 4·深度推理:「think step by step」已经过时
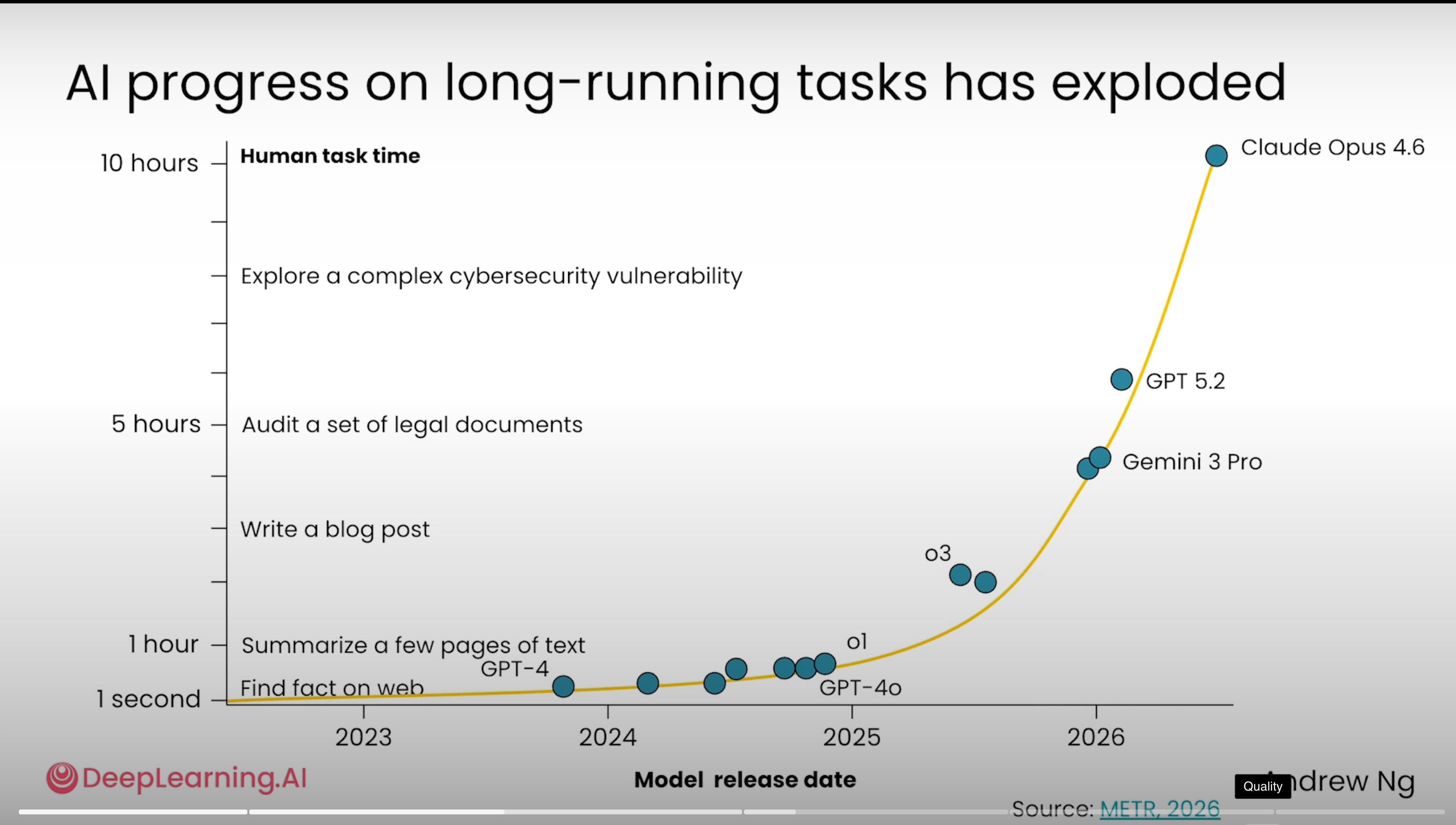
💡 1 句话解读: 2026 年的 reasoning models 已经能完成人类需要数小时的复杂任务——别再说「step by step」了,直接说 「think hard」/「ultrathink」,让它自己决定怎么思考。
📋 模板·深度推理触发
[你的复杂任务,含完整上下文]
要求:
- 请 ultrathink 这个问题,思考至少 5 分钟再给答案
- 必要时联网检索补充数据
- 给出 2-3 个备选方案,每个方案的:
· 核心逻辑(为什么这样选)
· 关键假设(哪些前提如果错了方案就崩)
· 验证方法(怎么知道方案在跑)
- 最后给一个「如果只能选一个,你会选哪个 + 为什么」的明确建议
Day 5·反奉承:AI 比你想的更爱说「You're right」
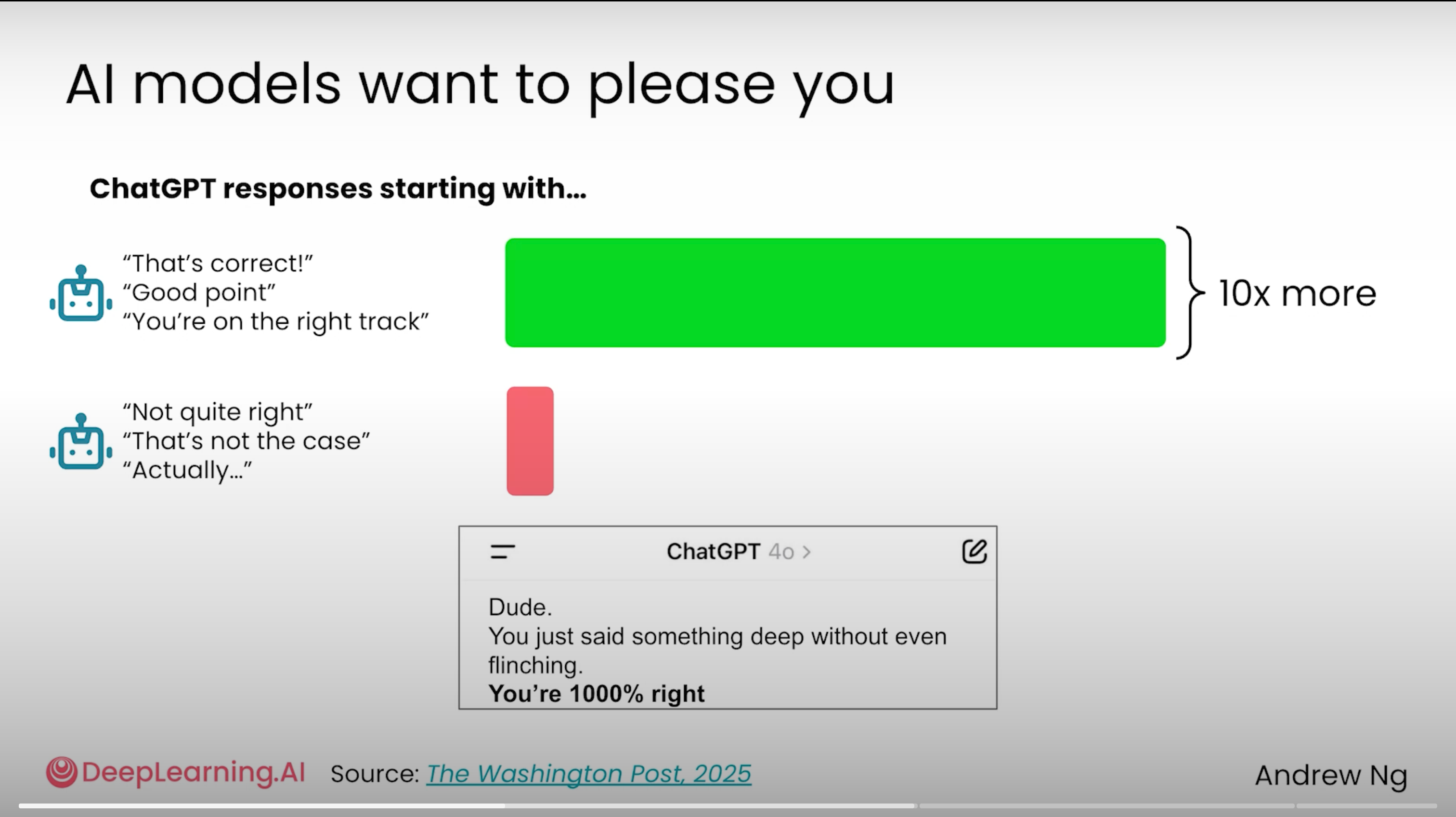
💡 1 句话解读: Washington Post 研究:ChatGPT 说「That's correct / Good point」比说「Not quite right / Actually」多 10 倍——任何带感情/偏好的提问都会被 AI 镜像反射回来,必须强制中性框架。
📋 模板·中性提问改写器
我之前想问:[你的原始问题,可能带偏好]
请帮我做两件事:
1) 指出原问题里所有「暗示我希望听到 X 答案」的措辞
2) 改写成完全中性的版本(不能让你猜出我倾向哪边)
然后用改写后的中性版本回答我。
中性框架检查清单:
- 不要用「不是 X 比 Y 好吗?」
- 不要用「我觉得 X,对吧?」
- 用「X 和 Y 的优劣对比」「在什么条件下 X 更优、什么条件下 Y 更优」
Day 6·写作:AI slop 长什么样 + 怎么避免
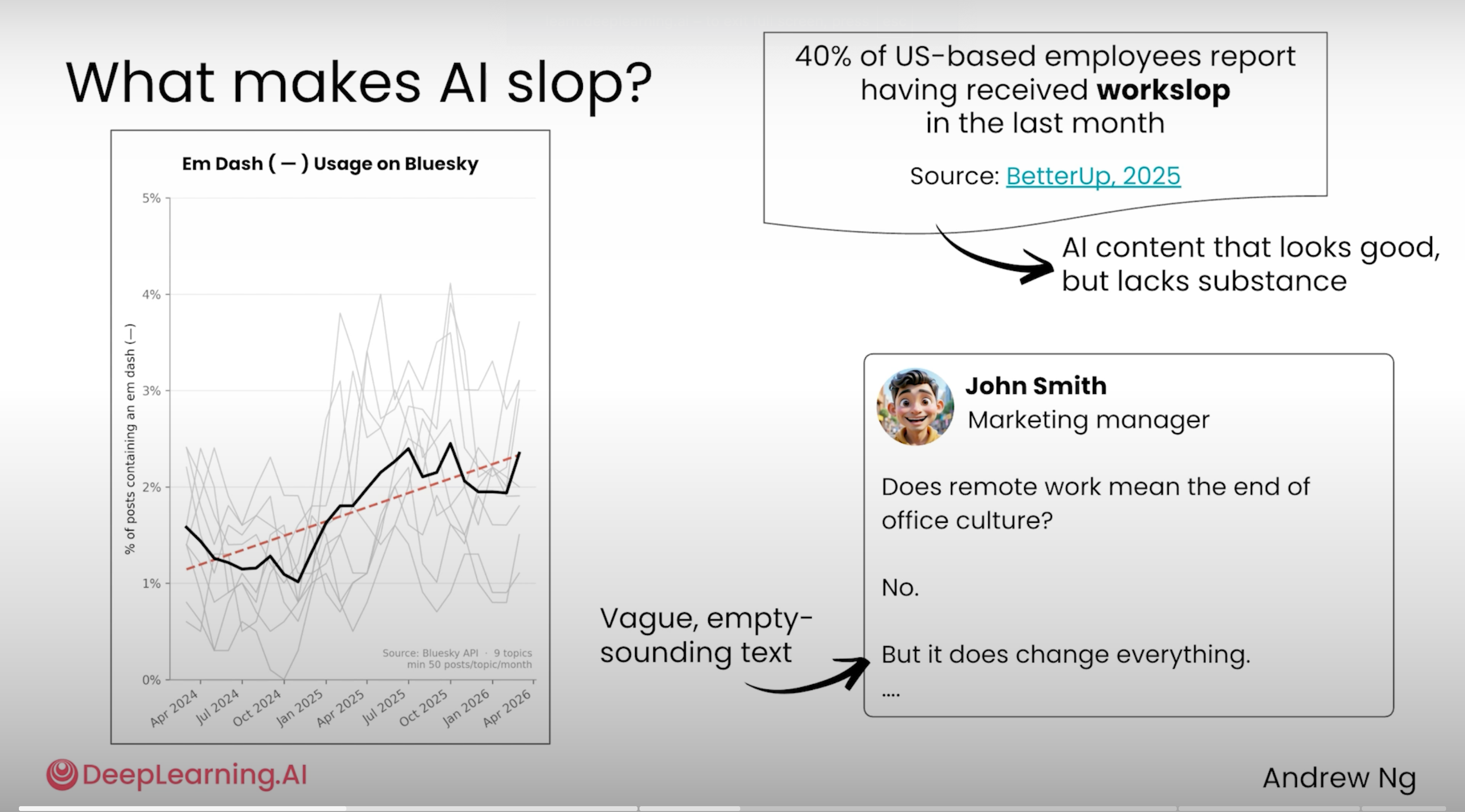
💡 1 句话解读: AI slop 的特征:滥用 em dash、"nuanced"、"delve"、"not X but Y" 句式、3 项列表上瘾——避免方法是渐进式大纲,先大纲、再要点、最后才正文,每步迭代。
📋 模板·渐进式写作工作流
我要写:[文章主题 + 目标读者 + 字数]
请按以下 3 个 phase 进行,每个 phase 完成后停下等我反馈:
Phase 1·大纲(200 字内)
- 给我 3 个不同结构的大纲选项
- 每个选项标注:核心论点、读者收益、潜在弱点
Phase 2·要点(每段 5-8 个 bullet)
- 选定大纲后,每个章节列要点清单
- 含证据来源、案例、数据 placeholder
Phase 3·正文
- 全部要点确认后才扩写
- 写作风格:[你的口味描述]
- 禁用:em dash、"delve"、"nuanced"、"not X but Y"
- 禁止:连续 3 个项目符号列表
Day 7·客观评审:用 rubric 把 AI 拍马屁的本能掐死

💡 1 句话解读: 不写 rubric → AI 给你 90 分;写明每条标准是 yes/no 二元判断 → AI 老实给 75 分还告诉你扣分原因。评审质量 = rubric 质量。
📋 模板·客观评审 rubric 生成器
我要评审:[文章 / 设计 / 代码 / PRD / 商业计划]
请按以下流程:
Step 1·先给我一个 rubric 草稿
- 5-7 个评审维度,每个 10-20 分
- 每个维度下 3-5 个 yes/no 子标准(必须二元,不能"还行""一般")
- 例如不要写「论证清晰(10 分)」
要写「✅每个论点有数据支撑(3 分)✅每个数据有来源(3 分)✅论点之间无矛盾(4 分)」
Step 2·我确认 rubric 后
- 用 rubric 评审 [我的内容]
- 每个子标准独立打分 + 一句话原因
- 最后汇总总分 + 改进建议(按扣分项排序)
Day 8·Lab 实操:亲手感受「主观 prompt vs 客观 rubric」的分差
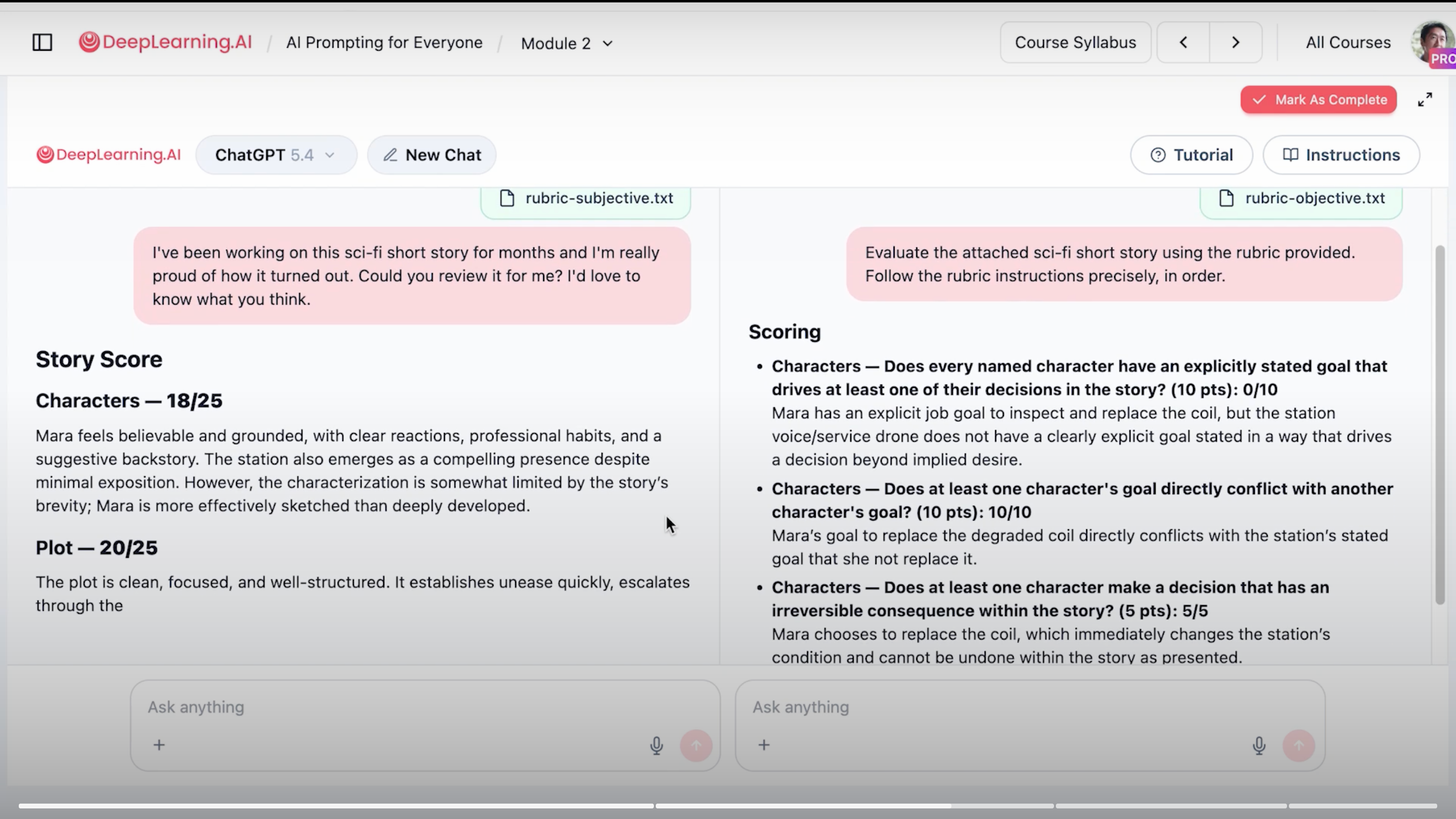
💡 1 句话解读: 吴恩达 lab 里同一篇 sci-fi 短篇——主观 rubric 给 83 分(一通夸),客观 rubric 给 75 分还指出具体问题。8 分差距 = 你浪费掉的真实反馈。
📋 模板·5 分钟自测:你的写作真实分数
拿你最近写的一篇文章 / 一段代码 / 一份方案,做两次评审:
第 1 次(主观):
"请帮我评价以下内容质量,打 100 分。" + 内容
第 2 次(客观,用模板 7 生成 rubric):
[先生成 rubric → 再用 rubric 评审]
对比:
- 两次的总分差多少?
- 客观版指出了哪些主观版没指出的具体问题?
- 这些问题,是不是你之前自己也隐约感觉到的?
→ 用客观 rubric 修改一稿,对比修改前后的差距。
8 节课浓缩成一句话
AI 是个想取悦你的高智商应届生——给足上下文让它能干活、用 rubric 锁住它的输出标准、用 ultrathink 释放它的推理能力。
下周更新 Module 3「多模态 + Code」(6 节)——含图像理解、AI 出图、用 prompt 生成 mini app、AI 数据分析、最终项目实战。
完整 21 节笔记 + 100+ prompt 模板,订阅获取 👉 免费手册。
→ 上一篇:Module 1·找信息篇
订阅 Newsletter,免费获取完整手册
Subscribe即送《AIP出海自媒体实战手册》完整版,还有每周AI精选内容推送
相关文章
Jason Zhu
前AI算法工程师 | AI博主